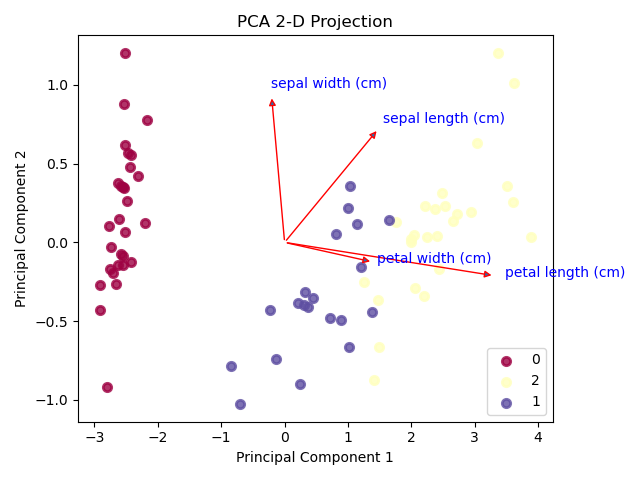
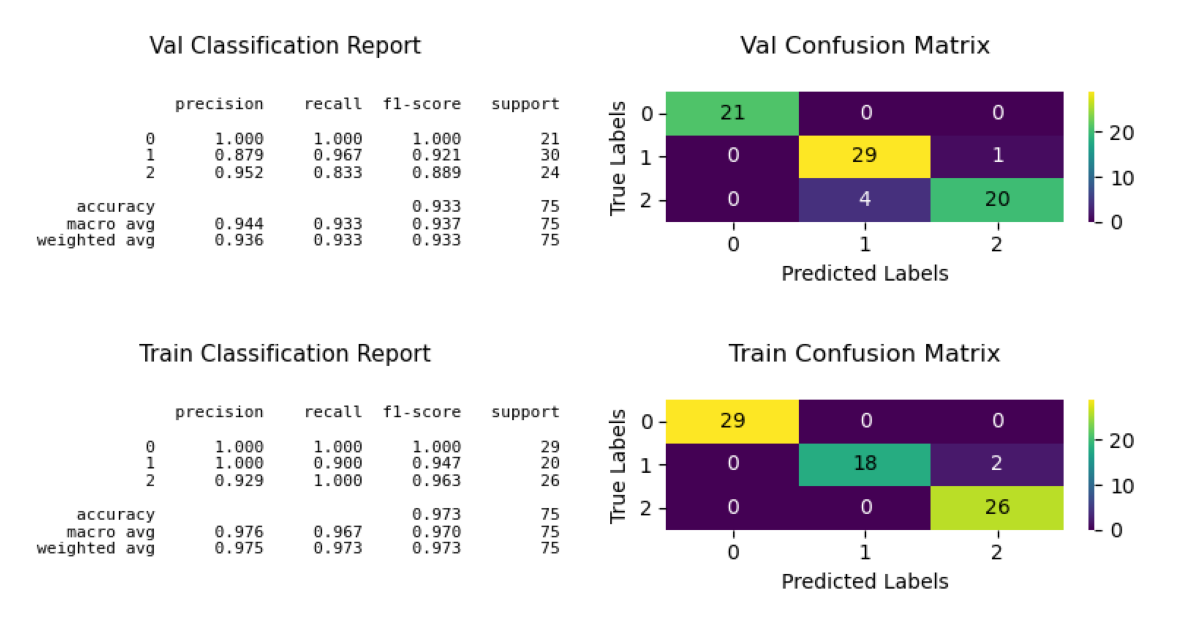
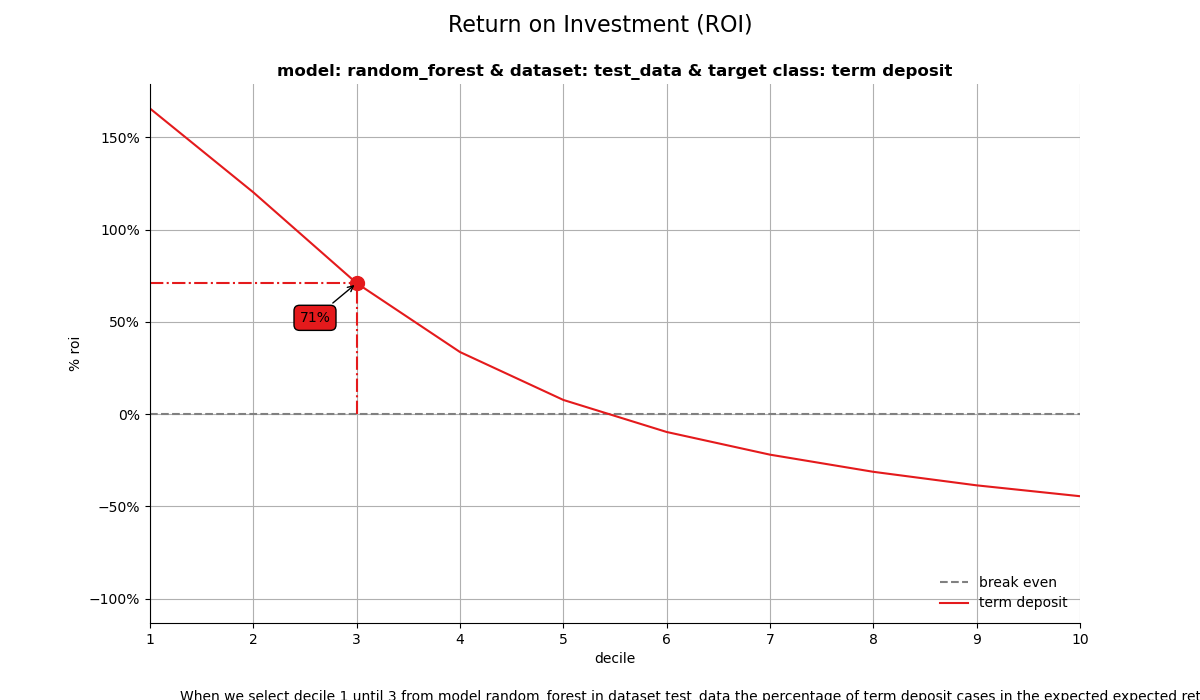
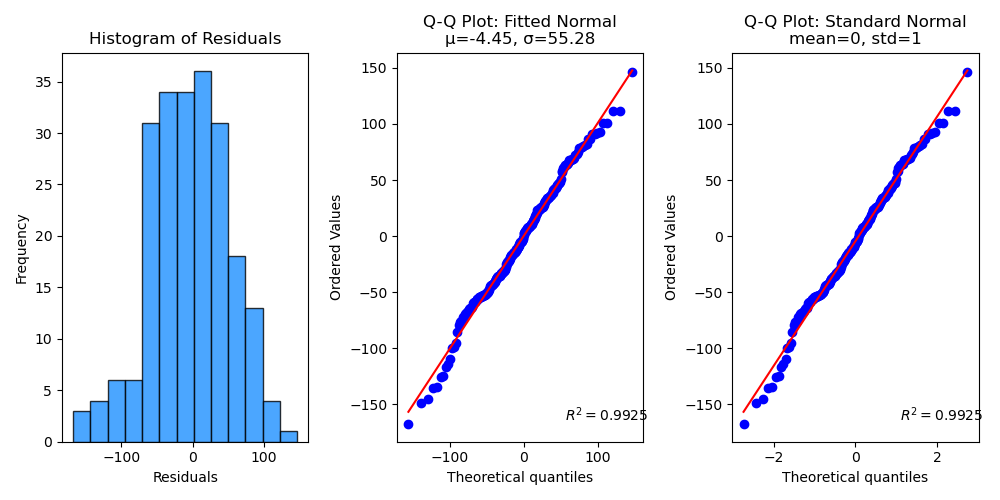
# Example code to try:
import micropip; await micropip.install("ipywidgets")
import io
import ipywidgets as widgets
import pandas as pd
from IPython.display import display
from sklearn.datasets import (
load_breast_cancer as data_2_classes,
load_iris as data_3_classes,
load_digits as data_10_classes,
make_classification,
)
upload = widgets.FileUpload(accept=".csv", multiple=False)
display(upload)
def process_file(change=None):
if not upload.value:
return
file_info = next(iter(upload.value))
return pd.read_csv(io.BytesIO(file_info["content"]))
upload.observe(
process_file,
names="value",
)
# Load the data
X, y = data_3_classes(return_X_y=True, as_frame=True)
X
To try the examples in the browser:
Type code in the input cell and press Shift + Enter to execute
Or copy-paste the code, and click on the Run button in the toolbar