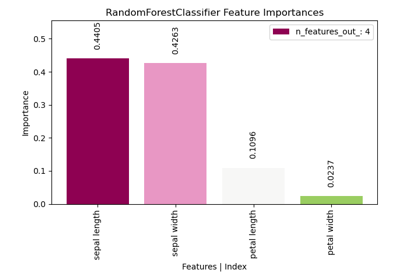
Introduction to modelplotpy#
To install the latest version (with pip):
>>> pip install scikit-learn scikit-plots --upgrade
>>> pip install numpy==1.26.4
This exercise is used in ModelPlotPy class the part of the
modelplotpy and modelplotpy financial sections.
References
A tutorial exercise example: Predictive models from sklearn on the Bank Marketing Data Set
This example is based on a publicly available dataset, called the Bank Marketing Data Set. It is one of the most popular datasets which is made available on the UCI Machine Learning Repository.
The data set comes from a Portuguese bank and deals with a frequently-posed marketing question: whether a customer did or did not acquire a term deposit, a financial product. There are 4 datasets available and the bank-additional-full.csv is the one we use. It contains the information of 41.188 customers and 21 columns of information.
To illustrate how to use modelplotpy, let’s say that we work for this bank and our marketing colleagues have asked us to help to select the customers that are most likely to respond to a term deposit offer. For that purpose, we will develop a predictive model and create the plots to discuss the results with our marketing colleagues. Since we want to show you how to build the plots, not how to build a perfect model, we’ll use six of these columns in our example.
Here’s a short description on the data we use:
y: has the client subscribed a term deposit?duration: last contact duration, in seconds (numeric)campaign: number of contacts performed during this campaign and for this clientpdays: number of days that passed by after the client was last contacted from a previous campaignprevious: number of contacts performed before this campaign and for this client (numeric)euribor3m: euribor 3 month rate
Let’s load the data and have a quick look at it:
# Authors: The scikit-plots developers
# SPDX-License-Identifier: BSD-3-Clause
Loading the dataset#
import io
import os
import zipfile
import warnings
warnings.filterwarnings("ignore")
import numpy as np
np.random.seed(0) # reproducibility
import requests
import pandas as pd
# You can change the path, currently the data is written to the working directory
path = os.getcwd()
# r = requests.get(
# "https://archive.ics.uci.edu/ml/machine-learning-databases/00222/bank-additional.zip"
# )
# we encountered that the source at uci.edu is not always available,
# therefore we made a copy to our repos.
r = requests.get("https://modelplot.github.io/img/bank-additional.zip")
z = zipfile.ZipFile(io.BytesIO(r.content))
z.extractall(path)
# Load csv data
bank = pd.read_csv(path + "/bank-additional/bank-additional-full.csv", sep=";")
# select the 6 columns
bank = bank[["y", "duration", "campaign", "pdays", "previous", "euribor3m"]]
# rename target class value 'yes' for better interpretation
bank.y[bank.y == "yes"] = "term deposit"
# dimensions of the data
print(bank.shape)
# show the first rows of the dataset
print(bank.head())
(41188, 6)
y duration campaign pdays previous euribor3m
0 no 261 1 999 0 4.857
1 no 149 1 999 0 4.857
2 no 226 1 999 0 4.857
3 no 151 1 999 0 4.857
4 no 307 1 999 0 4.857
Train models on the bank dataset#
On this data, we’ve applied some predictive modeling techniques from the sklearn module. This well known module is a wrapper for many predictive modeling techniques, such as logistic regression, random forest and many, many others. Lets train a few models to evaluate with our plots.
# to create predictive models
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# define target vector y
y = bank.y
# define feature matrix X
X = bank.drop("y", axis=1)
# Create the necessary datasets to build models
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=2018
)
# Instantiate a few classification models
clf_rf = RandomForestClassifier().fit(X_train, y_train)
clf_mult = LogisticRegression(random_state=0).fit(
X_train, y_train
)
Plotting partial dependence for two features#
For now, we focus on explaining to our marketing colleagues how good our predictive model can help them select customers for their term deposit campaign.
import scikitplot.modelplotpy as mp
# from scikitplot import modelplotpy as mp
obj = mp.ModelPlotPy(
feature_data=[X_train, X_test],
label_data=[y_train, y_test],
dataset_labels=["train_data", "test_data"],
models=[clf_rf, clf_mult],
model_labels=["random_forest", "multinomial_logit"],
ntiles=10,
)
# transform data generated with prepare_scores_and_deciles into aggregated data for chosen plotting scope
ps = obj.plotting_scope(
select_model_label=["random_forest"], select_dataset_label=["test_data"]
)
Default scope value no_comparison selected, single evaluation line will be plotted.
The label with smallest class is term deposit
Target class term deposit, dataset test_data and model random_forest.
What just happened? In the modelplotpy a class is instantiated and the plotting_scope function specifies the scope of the plots you want to show. In general, there are 3 methods (functions) that can be applied to the modelplotpy class but you don’t have to specify them since they are chained to each other.
These functions are:
prepare_scores_and_deciles: scores the customers in the train dataset and test dataset with their probability to acquire a term depositaggregate_over_deciles: aggregates all scores to deciles and calculates the information to showplotting_scope: allows you to specify the scope of the analysis.
In the second line of code, we specified the scope of the analysis. We’ve not specified the “scope” parameter, therefore the default - no comparison - is chosen. As the output notes, you can use modelplotpy to evaluate your model(s) from several perspectives:
Interpret just one model (the default)Compare the model performance across different datasetsCompare the performance across different modelsCompare the performance across different target classes
Here, we will keep it simple and evaluate - from a business perspective - how well a selected model
will perform in a selected dataset for one target class. We did specify values for some parameters,
to focus on the random forest model on the test data. The default value for the target class is
term deposit since we want to focus on customers that do take term deposits,
this default is perfect.
Let’s introduce the Gains, Lift and (cumulative) Response plots.#
Although each plot sheds light on the business value of your model from a different angle, they all use the same data:
Predicted probability for the target class
Equally sized groups based on this predicted probability
Actual number of observed target class observations in these groups
1. Cumulative gains plot#
The cumulative gains plot - often named ‘gains plot’ - helps you answer the question:
When we apply the model and select the best X deciles, what % of the actual target class observations can we expect to target?
# plot the cumulative gains plot and annotate the plot at decile = 3
ax = mp.plot_cumgains(ps, highlight_ntile=3, save_fig=True)
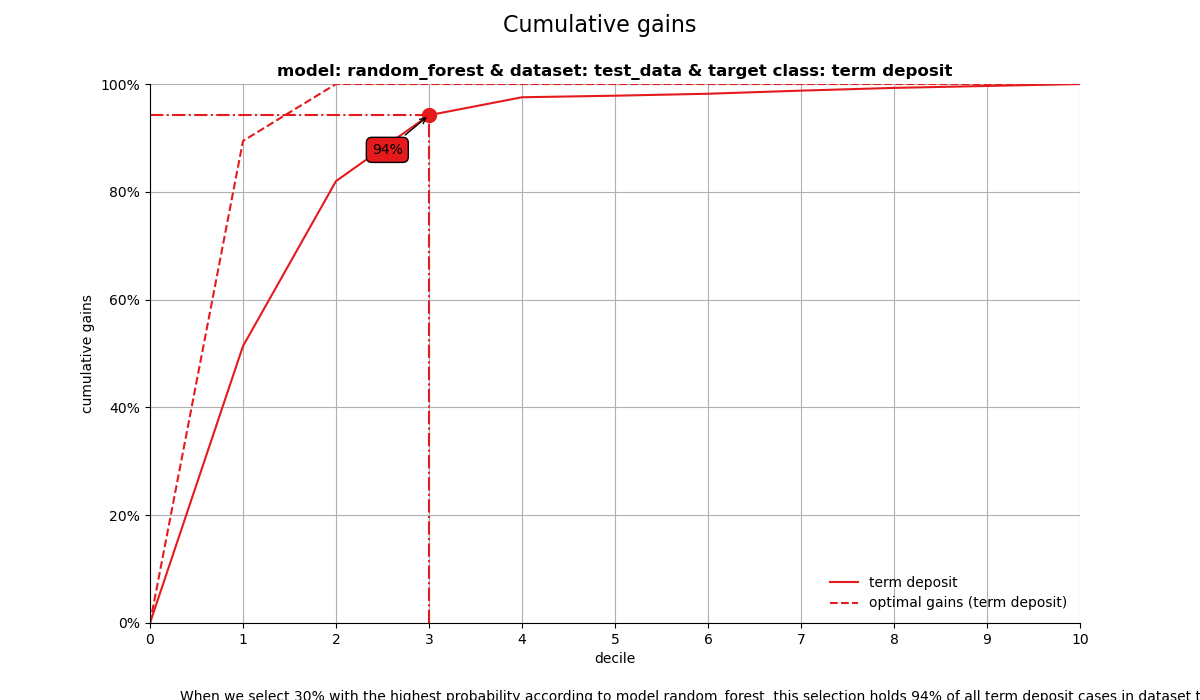
When we select 30% with the highest probability according to model random_forest, this selection holds 93% of all term deposit cases in dataset test_data.
2. Cumulative lift plot#
The cumulative lift plot, often referred to as lift plot or index plot, helps you answer the question:
When we apply the model and select the best X deciles, how many times better is that than using no model at all?
# plot the cumulative lift plot and annotate the plot at decile = 3
ax = mp.plot_cumlift(ps, highlight_ntile=3, save_fig=True)
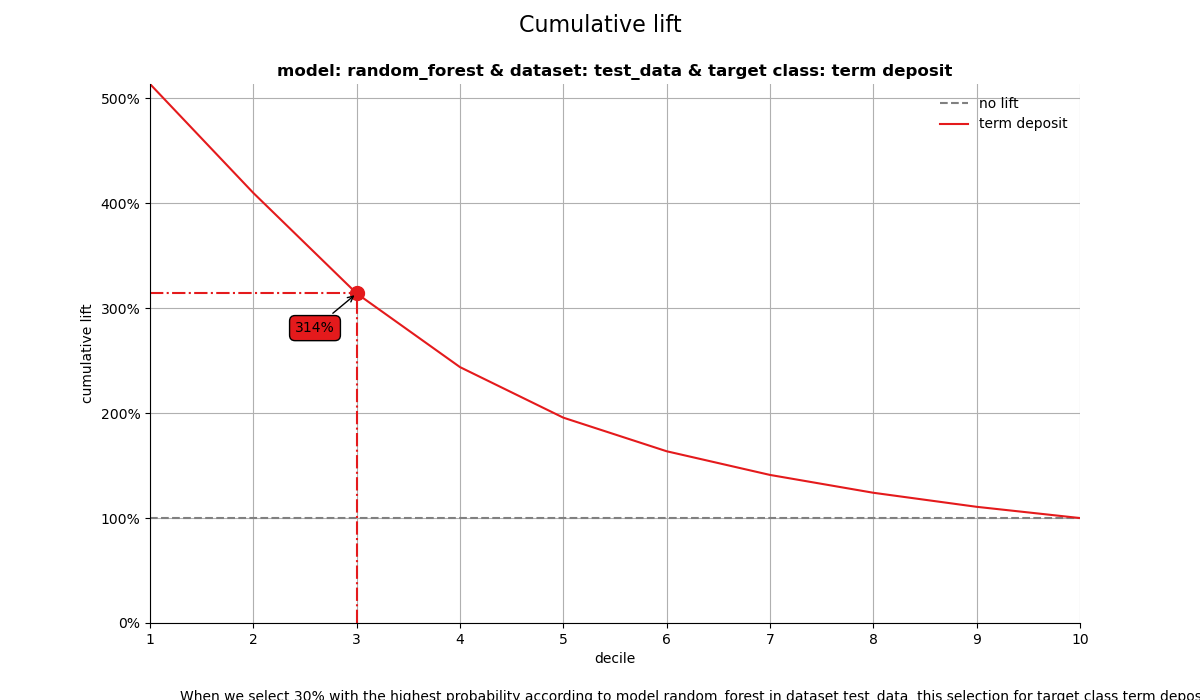
When we select 30% with the highest probability according to model random_forest in dataset test_data, this selection for target class term deposit is 3.13 times than selecting without a model.
3. Response plot#
One of the easiest to explain evaluation plots is the response plot. It simply plots the percentage of target class observations per decile. It can be used to answer the following business question:
When we apply the model and select decile X, what is the expected % of target class observations in that decile?
# plot the response plot and annotate the plot at decile = 3
ax = mp.plot_response(ps, highlight_ntile=3, save_fig=True)
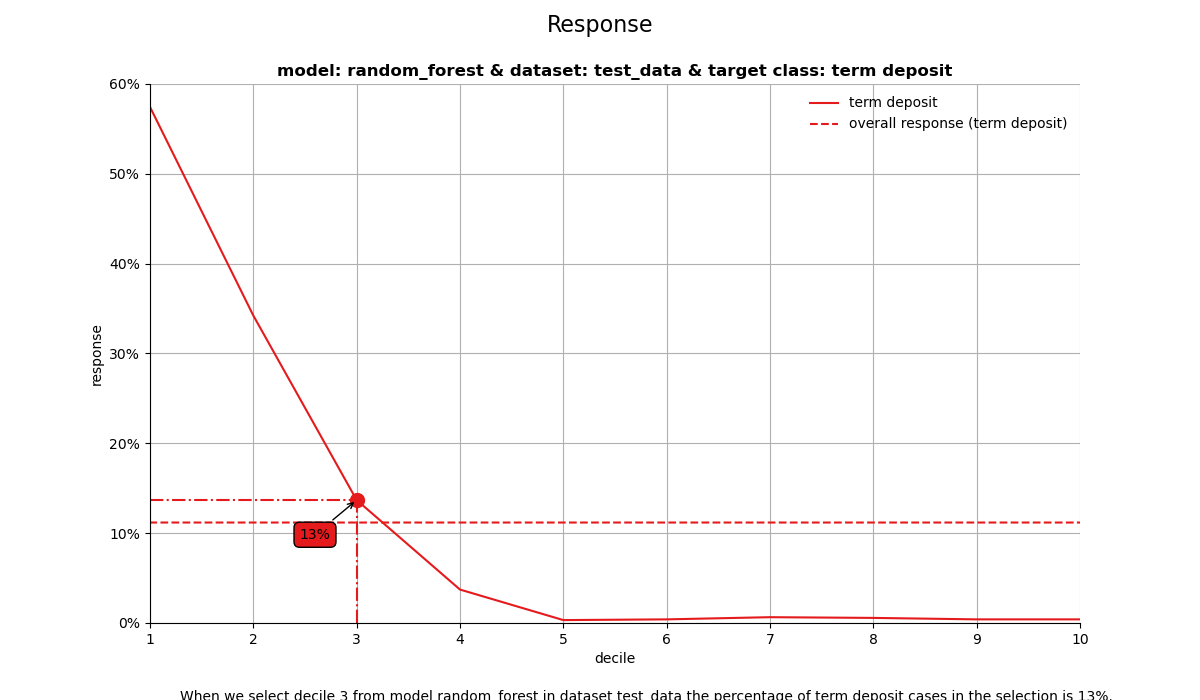
When we select decile 3 from model random_forest in dataset test_data the percentage of term deposit cases in the selection is 13%.
4. Cumulative response plot#
Finally, one of the most used plots: The cumulative response plot. It answers the question burning on each business reps lips:
When we apply the model and select up until decile X, what is the expected % of target class observations in the selection?
# plot the cumulative response plot and annotate the plot at decile = 3
ax = mp.plot_cumresponse(ps, highlight_ntile=3, save_fig=True)
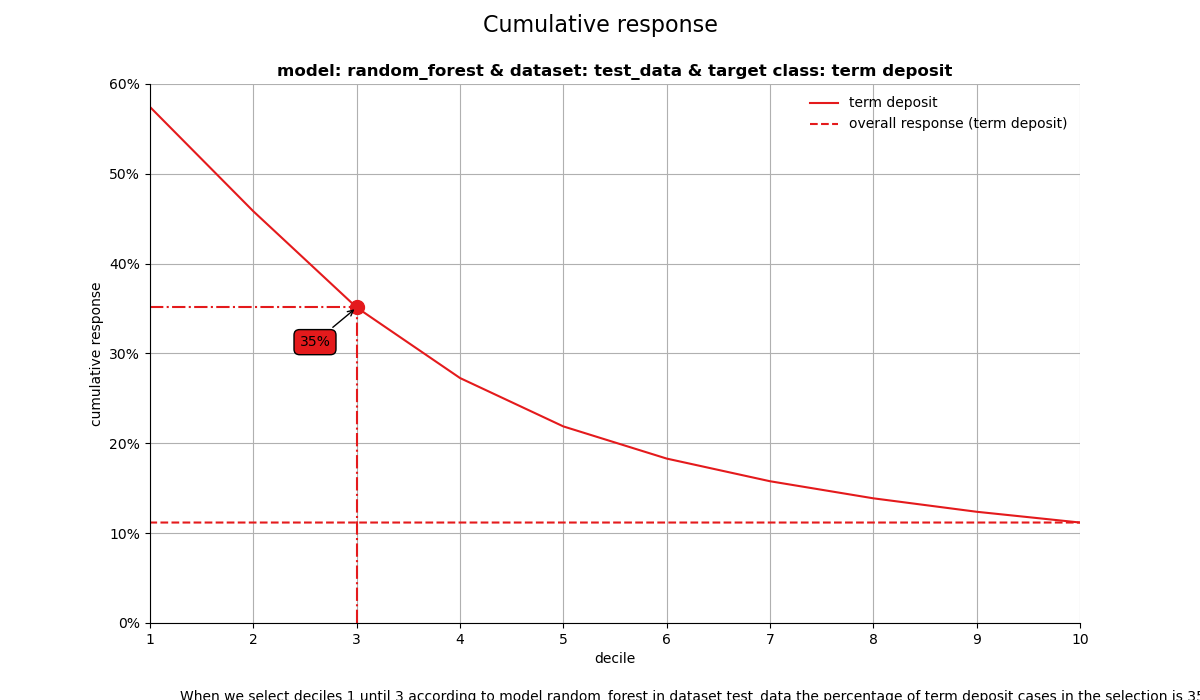
When we select deciles 1 until 3 according to model random_forest in dataset test_data the percentage of term deposit cases in the selection is 35%.
All four plots together#
With the function call plot_all we get all four plots on one grid. We can easily save it to a file to include it in a presentation or share it with colleagues.
# plot all four evaluation plots and save to file
ax = mp.plot_all(
ps,
save_fig=True,
overwrite=False,
add_timestamp=True,
verbose=True,
)
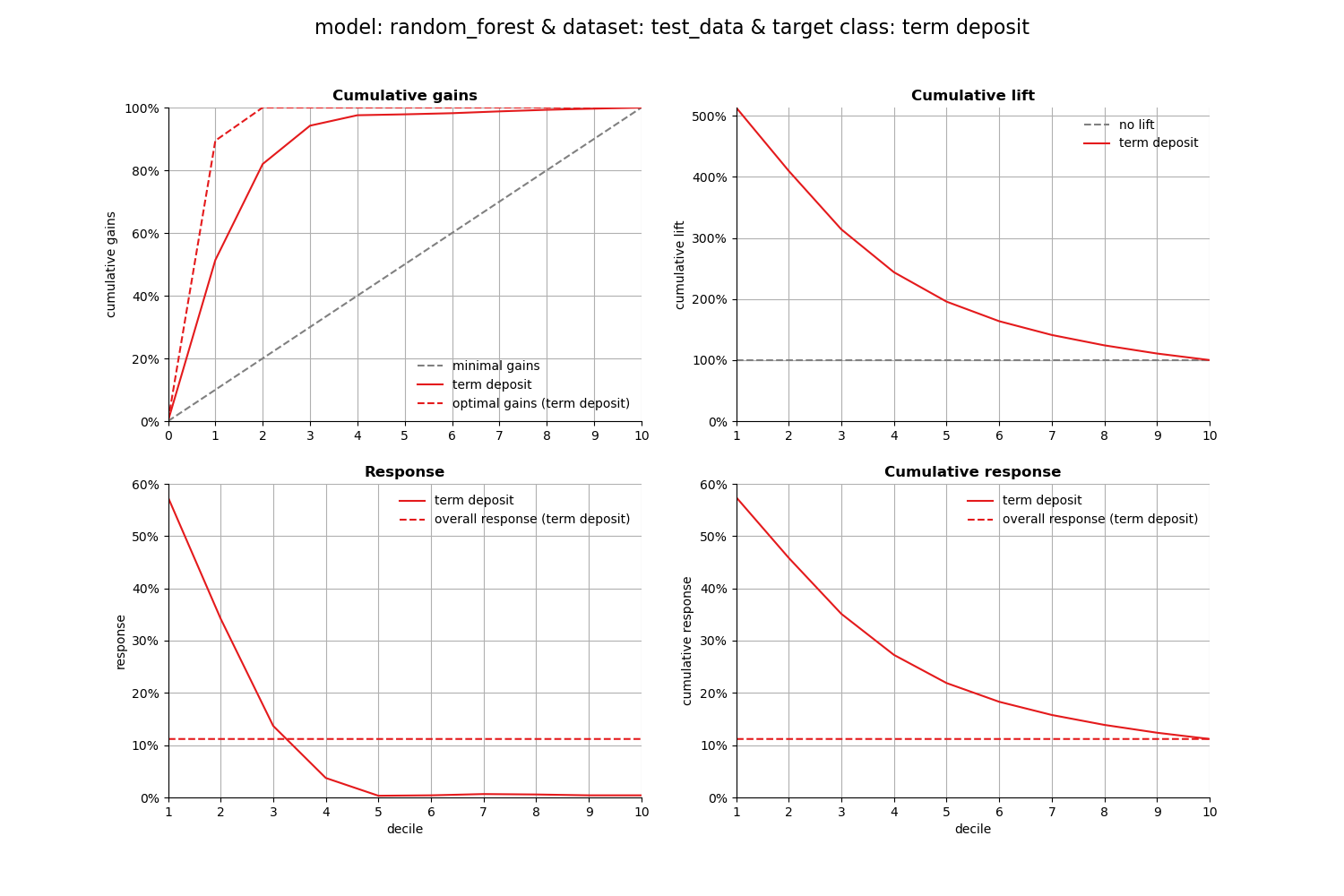
[INFO] Saving path to: /home/circleci/repo/galleries/examples/modelplotpy/result_images/plot_all_20260106_165550Z.png
[INFO] Plot saved to: /home/circleci/repo/galleries/examples/modelplotpy/result_images/plot_all_20260106_165550Z.png
Financial Implications#
To plot the financial implications of implementing a predictive model, modelplotr provides three additional plots: the Costs & revenues plot, the Profit plot and the ROI plot.
For financial plots, three extra parameters need to be provided:
1. Return on investment plot#
The Return on Investment plot plots the cumulative revenues as a percentage of investments up until that decile when the model is used for campaign selection. It can be used to answer the following business question:
When we apply the model and select up until decile X, what is the expected % return on investment of the campaign?
# Return on Investment (ROI) plot
ax = mp.plot_roi(
ps,
fixed_costs=1000,
variable_costs_per_unit=10,
profit_per_unit=50,
highlight_ntile=3,
save_fig=True,
)
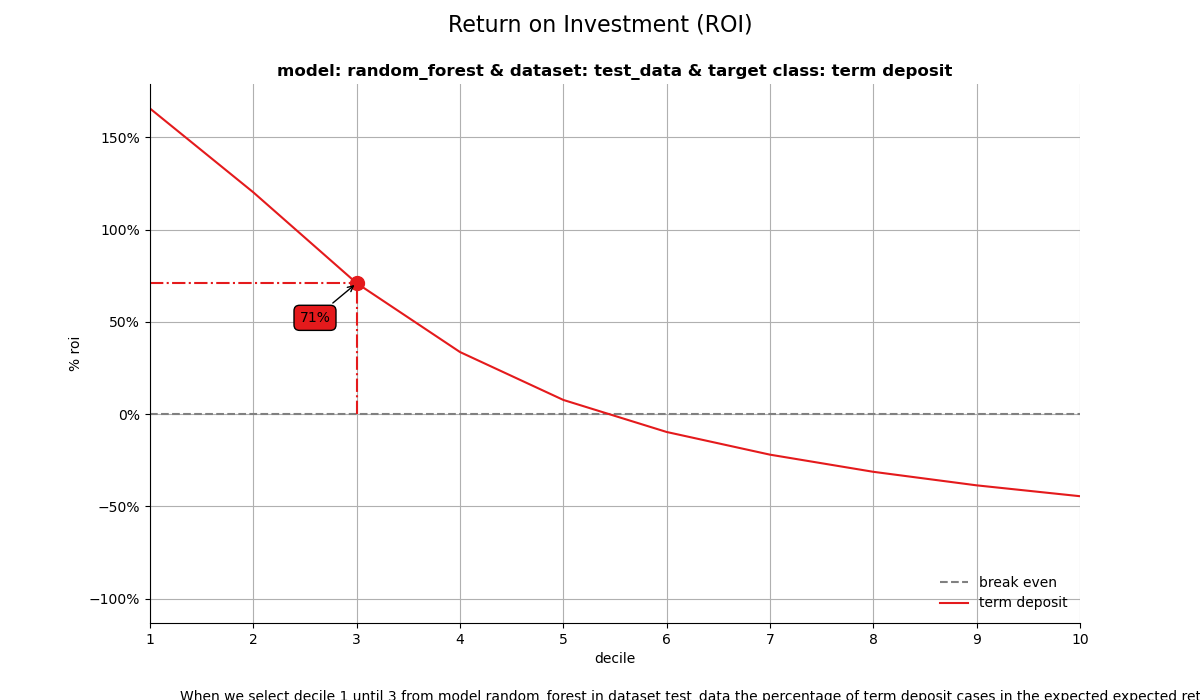
When we select decile 1 until 3 from model random_forest in dataset test_data the percentage of term deposit cases in the expected expected return on investment is 70%.
2. Costs & Revenues plot#
The costs & revenues plot plots both the cumulative revenues and the cumulative costs (investments) up until that decile when the model is used for campaign selection. It can be used to answer the following business question:
When we apply the model and select up until decile X, what are the expected revenues and investments of the campaign?
# Costs & Revenues plot, highlighted at max roi instead of max profit
ax = mp.plot_costsrevs(
ps,
fixed_costs=1000,
variable_costs_per_unit=10,
profit_per_unit=50,
highlight_ntile=3,
# highlight_ntile = "max_roi",
save_fig=True,
)
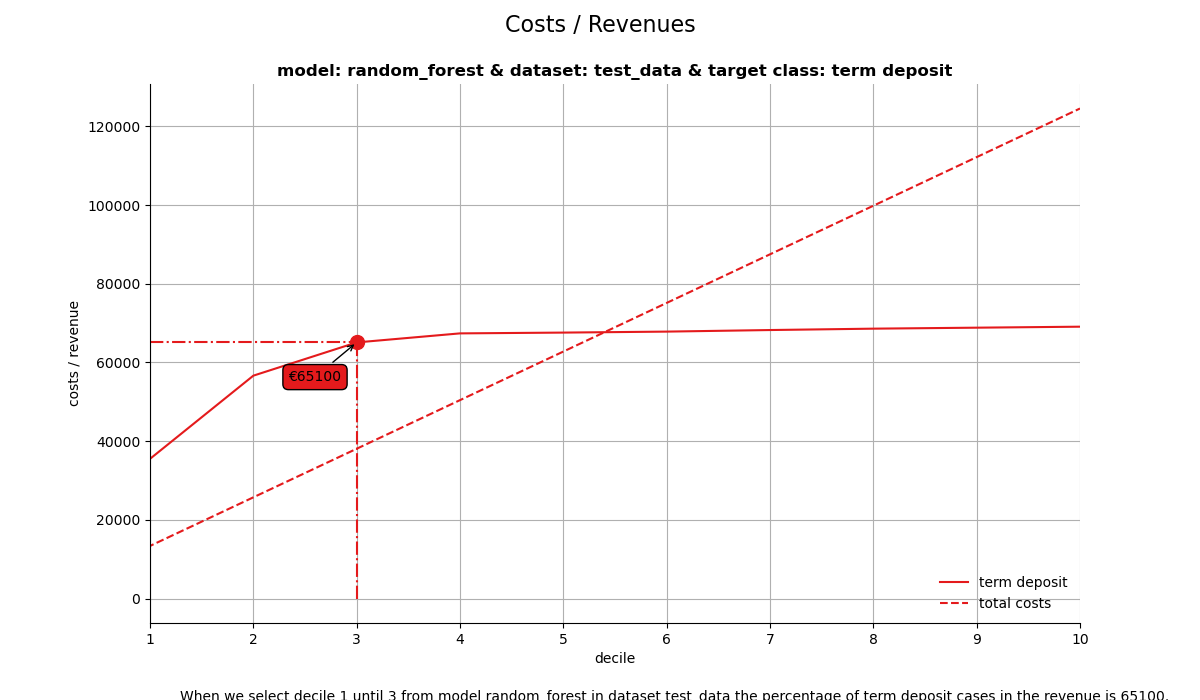
When we select decile 1 until 3 from model random_forest in dataset test_data the percentage of term deposit cases in the revenue is 64950.
3. Profit plot#
The profit plot visualized the cumulative profit up until that decile when the model is used for campaign selection. It can be used to answer the following business question:
When we apply the model and select up until decile X, what is the expected profit of the campaign?
# Profit plot , highlighted at custom ntile instead of at max profit
ax = mp.plot_profit(
ps,
fixed_costs=1000,
variable_costs_per_unit=10,
profit_per_unit=50,
highlight_ntile=3,
save_fig=True,
)
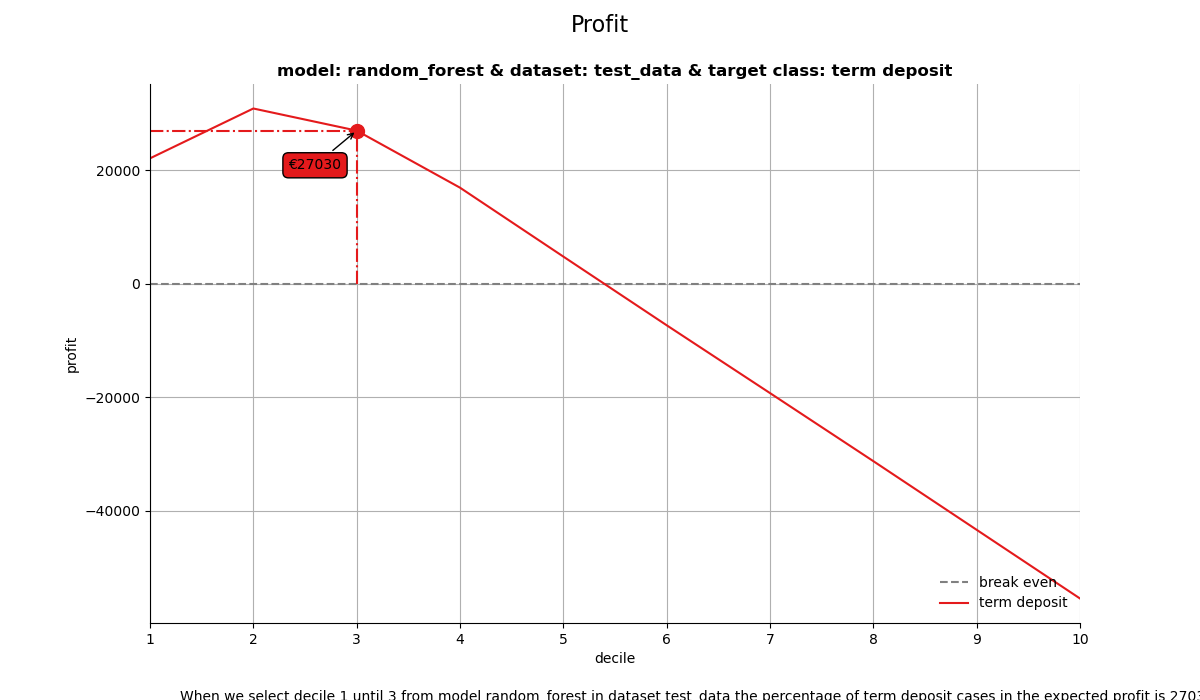
When we select decile 1 until 3 from model random_forest in dataset test_data the percentage of term deposit cases in the expected profit is 26880.
Get more out of modelplotpy: using different scopes#
As we mentioned discussed earlier, the modelplotpy also enables to make interesting comparisons, using the scope parameter. Comparisons between different models, between different datasets and (in case of a multiclass target) between different target classes. Curious? Please have a look at the package documentation or read our other posts on modelplot.
1. compare_models#
However, to give one example, we could compare whether random forest was indeed the best choice to select the top-30% customers for a term deposit offer:
ps2 = obj.plotting_scope(scope="compare_models", select_dataset_label=["test_data"])
# plot the cumulative response plot and annotate the plot at decile = 3
ax = mp.plot_cumresponse(ps2, highlight_ntile=3, save_fig=True)
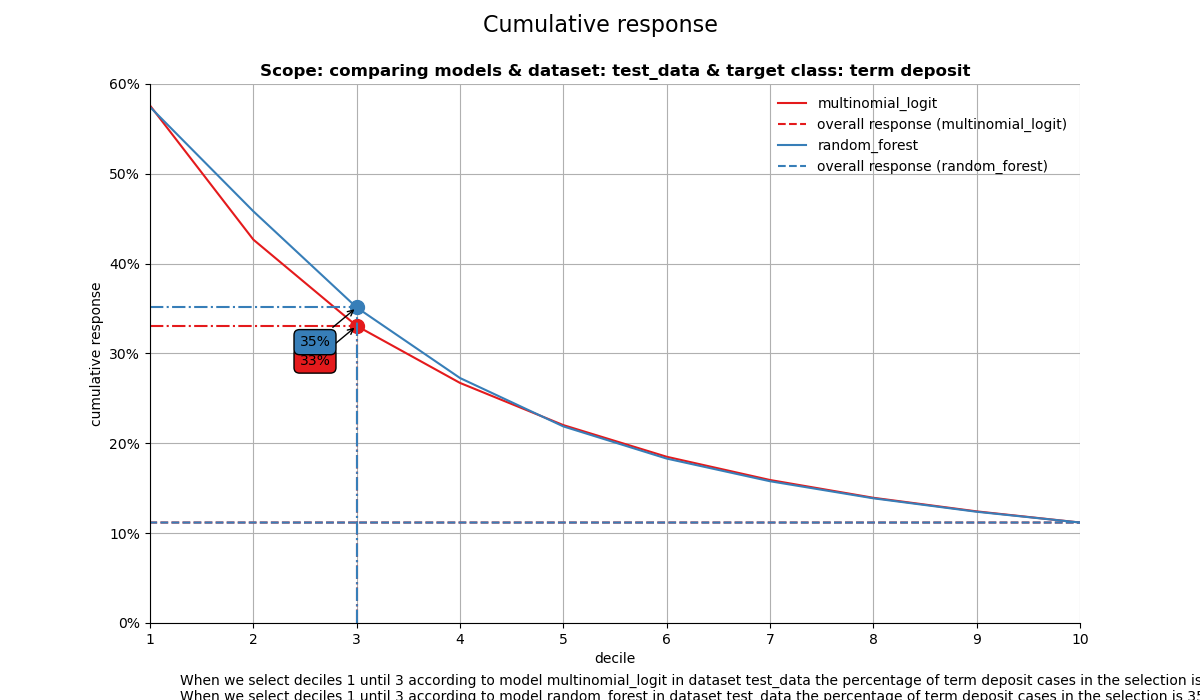
compare models
The label with smallest class is ['term deposit']
When we select deciles 1 until 3 according to model multinomial_logit in dataset test_data the percentage of term deposit cases in the selection is 33%.
When we select deciles 1 until 3 according to model random_forest in dataset test_data the percentage of term deposit cases in the selection is 35%.
import scikitplot as sp
sp.remove_path()
Seems like the algorithm used will not make a big difference in this case. Hopefully you agree by now that using these plots really can make a difference in explaining the business value of your predictive models!
In case you experience issues when using modelplotpy, please let us know via the issues section on Github. Any other feedback or suggestions, please let us know via pb.marcus or jurriaan.nagelkerke.
Happy modelplotting!
Total running time of the script: (0 minutes 8.771 seconds)
Related examples