visualkeras: autoencoder example#
An example showing the visualkeras function
used by a tf.keras.Model model.
# Authors: The scikit-plots developers
# SPDX-License-Identifier: BSD-3-Clause
# visualkeras Need aggdraw tensorflow
# !pip install scikitplot[core, cpu]
# or
# !pip install aggdraw
# !pip install tensorflow
# pip install protobuf==5.29.4
import tensorflow as tf
# Clear any session to reset the state of TensorFlow/Keras
tf.keras.backend.clear_session()
/home/circleci/.pyenv/versions/3.11.14/lib/python3.11/site-packages/keras/src/export/tf2onnx_lib.py:8: FutureWarning:
In the future `np.object` will be defined as the corresponding NumPy scalar.
encoder Model
encoder_input = tf.keras.Input(shape=(28, 28, 1), name="img")
x = tf.keras.layers.Conv2D(16, 3, activation="relu")(encoder_input)
x = tf.keras.layers.Conv2D(32, 3, activation="relu")(x)
x = tf.keras.layers.MaxPooling2D(3)(x)
x = tf.keras.layers.Conv2D(32, 3, activation="relu")(x)
x = tf.keras.layers.Conv2D(16, 3, activation="relu")(x)
encoder_output = tf.keras.layers.GlobalMaxPooling2D()(x)
encoder = tf.keras.Model(encoder_input, encoder_output, name="encoder")
# autoencoder Model
x = tf.keras.layers.Reshape((4, 4, 1))(encoder_output)
x = tf.keras.layers.Conv2DTranspose(16, 3, activation="relu")(x)
x = tf.keras.layers.Conv2DTranspose(32, 3, activation="relu")(x)
x = tf.keras.layers.UpSampling2D(3)(x)
x = tf.keras.layers.Conv2DTranspose(16, 3, activation="relu")(x)
decoder_output = tf.keras.layers.Conv2DTranspose(1, 3, activation="relu")(x)
autoencoder = tf.keras.Model(encoder_input, decoder_output, name="autoencoder")
autoencoder.summary()
Model: "autoencoder"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ img (InputLayer) │ (None, 28, 28, 1) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ conv2d (Conv2D) │ (None, 26, 26, 16) │ 160 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ conv2d_1 (Conv2D) │ (None, 24, 24, 32) │ 4,640 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ max_pooling2d (MaxPooling2D) │ (None, 8, 8, 32) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ conv2d_2 (Conv2D) │ (None, 6, 6, 32) │ 9,248 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ conv2d_3 (Conv2D) │ (None, 4, 4, 16) │ 4,624 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ global_max_pooling2d │ (None, 16) │ 0 │
│ (GlobalMaxPooling2D) │ │ │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ reshape (Reshape) │ (None, 4, 4, 1) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ conv2d_transpose │ (None, 6, 6, 16) │ 160 │
│ (Conv2DTranspose) │ │ │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ conv2d_transpose_1 │ (None, 8, 8, 32) │ 4,640 │
│ (Conv2DTranspose) │ │ │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ up_sampling2d (UpSampling2D) │ (None, 24, 24, 32) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ conv2d_transpose_2 │ (None, 26, 26, 16) │ 4,624 │
│ (Conv2DTranspose) │ │ │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ conv2d_transpose_3 │ (None, 28, 28, 1) │ 145 │
│ (Conv2DTranspose) │ │ │
└─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 28,241 (110.32 KB)
Trainable params: 28,241 (110.32 KB)
Non-trainable params: 0 (0.00 B)
Build the model with an explicit input shape
autoencoder.build(
input_shape=(None, 28, 28, 1)
) # Batch size of None, shape (28, 28, 1)
# Create a dummy input tensor with a batch size of 1
dummy_input = tf.random.normal([1, 28, 28, 1]) # Batch size of 1, shape (28, 28, 1)
# Run the dummy input through the model to trigger shape calculation
encoder_output = autoencoder(dummy_input)
# Now check the output shape of the encoder
print("Output shape after running model with dummy input:", encoder_output.shape)
# Check each layer's output shape after building the model
for layer in encoder.layers:
if hasattr(layer, "output_shape"):
print(f"{layer.name} output shape: {layer.output_shape}")
if hasattr(layer, "output"):
print(f"{layer.name} shape: {layer.output.shape}")
Output shape after running model with dummy input: (1, 28, 28, 1)
img shape: (None, 28, 28, 1)
conv2d shape: (None, 26, 26, 16)
conv2d_1 shape: (None, 24, 24, 32)
max_pooling2d shape: (None, 8, 8, 32)
conv2d_2 shape: (None, 6, 6, 32)
conv2d_3 shape: (None, 4, 4, 16)
global_max_pooling2d shape: (None, 16)
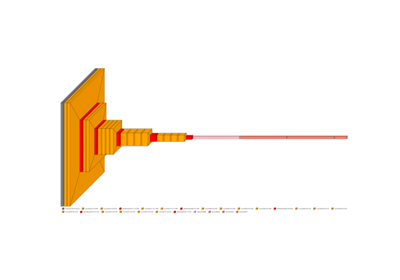
from scikitplot import visualkeras
img_encoder = visualkeras.layered_view(
encoder,
text_callable="default",
# to_file="result_images/encoder.png",
save_fig=True,
save_fig_filename="encoder.png",
)
img_encoder
2026-01-06 16:56:15.716688: W scikitplot 140172358323072 utils_pil.py:204:load_font] Error loading system font: cannot open resource
2026-01-06 16:56:15.716780: W scikitplot 140172358323072 utils_pil.py:206:load_font] Falling back to PIL default font.
2026-01-06 16:56:15.716891: W scikitplot 140172358323072 _layered.py:216:layered_view] The legend_text_spacing_offset parameter is deprecated andwill be removed in a future release.
<matplotlib.image.AxesImage object at 0x7f7bac2e3190>
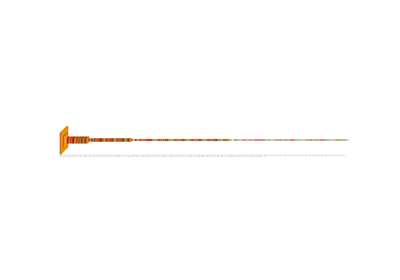
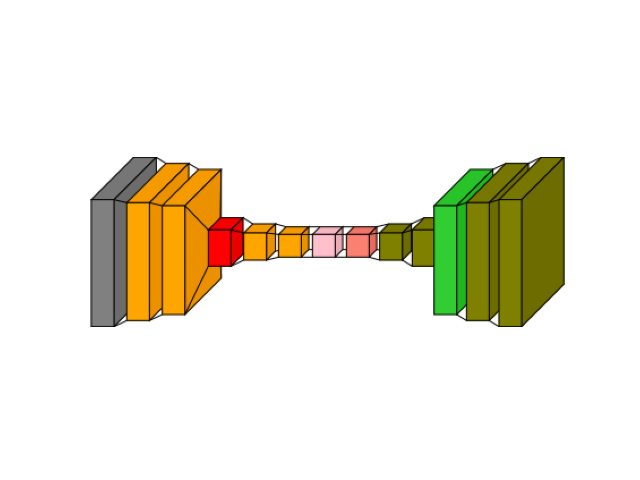
img_autoencoder = visualkeras.layered_view(
autoencoder,
# to_file="result_images/autoencoder.png",
save_fig=True,
save_fig_filename="autoencoder.png",
)
img_autoencoder
2026-01-06 16:56:15.906558: W scikitplot 140172358323072 utils_pil.py:204:load_font] Error loading system font: cannot open resource
2026-01-06 16:56:15.906680: W scikitplot 140172358323072 utils_pil.py:206:load_font] Falling back to PIL default font.
2026-01-06 16:56:15.906808: W scikitplot 140172358323072 _layered.py:216:layered_view] The legend_text_spacing_offset parameter is deprecated andwill be removed in a future release.
<matplotlib.image.AxesImage object at 0x7f7b9408b190>
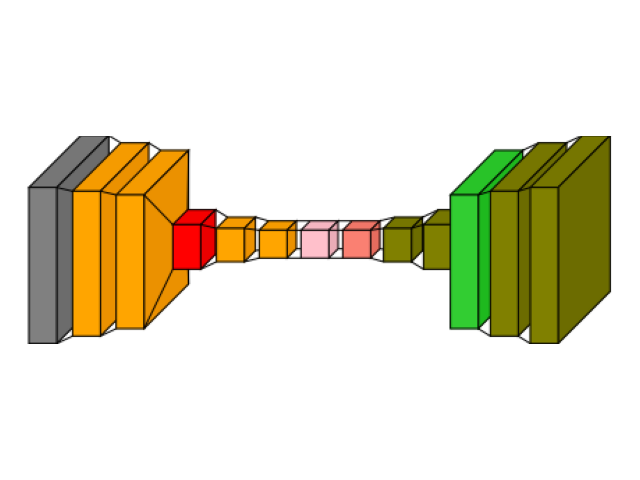
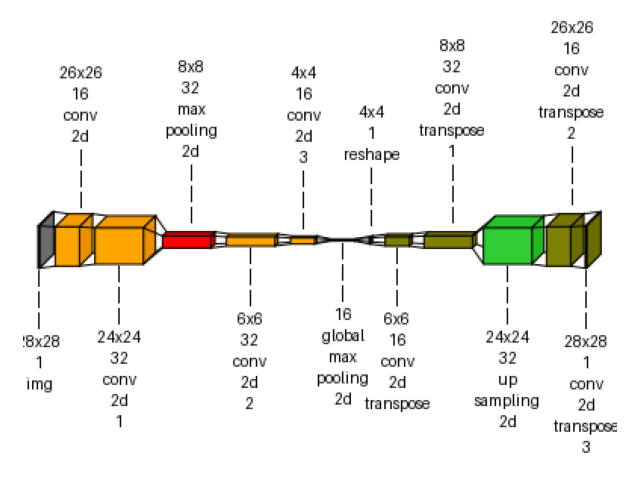
img_autoencoder_text = visualkeras.layered_view(
autoencoder,
min_z=1,
min_xy=1,
max_z=4096,
max_xy=4096,
scale_z=1,
scale_xy=1,
# font={"font_size": 14},
text_callable="default",
# to_file="result_images/autoencoder_text.png",
save_fig=True,
save_fig_filename="autoencoder_text.png",
overwrite=False,
add_timestamp=True,
verbose=True,
)
img_autoencoder_text
2026-01-06 16:56:16.057579: W scikitplot 140172358323072 utils_pil.py:204:load_font] Error loading system font: cannot open resource
2026-01-06 16:56:16.057785: W scikitplot 140172358323072 utils_pil.py:206:load_font] Falling back to PIL default font.
2026-01-06 16:56:16.057995: W scikitplot 140172358323072 _layered.py:216:layered_view] The legend_text_spacing_offset parameter is deprecated andwill be removed in a future release.
[INFO] Saving path to: /home/circleci/repo/galleries/examples/visualkeras_CNN/result_images/autoencoder_text_20260106_165616Z.png
<matplotlib.image.AxesImage object at 0x7f7b940bb590>
Total running time of the script: (0 minutes 3.689 seconds)
Related examples
Visualkeras: Spam Classification Conv1D Dense Example
Visualkeras: Spam Classification Conv1D Dense Example