visualkeras: transformers example#
An example showing the visualkeras function
used by a tf.keras.Model or Module or
TFPreTrainedModel model.
10 # Authors: The scikit-plots developers
11 # SPDX-License-Identifier: BSD-3-Clause
pip install protobuf==5.29.4
15 import tensorflow as tf
16
17 # Clear any session to reset the state of TensorFlow/Keras
18 tf.keras.backend.clear_session()
19
20 from transformers import TFAutoModel
21
22 from scikitplot import visualkeras
Load the Hugging Face transformer model
26 transformer_model = TFAutoModel.from_pretrained("microsoft/mpnet-base")
27
28
29 # Define a Keras-compatible wrapper for the Hugging Face model
30 def wrap_transformer_model(inputs):
31 input_ids, attention_mask = inputs
32 outputs = transformer_model(input_ids=input_ids, attention_mask=attention_mask)
33 return outputs.last_hidden_state # Return the last hidden state for visualization
TensorFlow and JAX classes are deprecated and will be removed in Transformers v5. We recommend migrating to PyTorch classes or pinning your version of Transformers.
Some weights of the PyTorch model were not used when initializing the TF 2.0 model TFMPNetModel: ['lm_head.layer_norm.weight', 'lm_head.layer_norm.bias', 'lm_head.dense.weight', 'lm_head.decoder.weight', 'lm_head.decoder.bias', 'lm_head.bias', 'lm_head.dense.bias']
- This IS expected if you are initializing TFMPNetModel from a PyTorch model trained on another task or with another architecture (e.g. initializing a TFBertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing TFMPNetModel from a PyTorch model that you expect to be exactly identical (e.g. initializing a TFBertForSequenceClassification model from a BertForSequenceClassification model).
Some weights or buffers of the TF 2.0 model TFMPNetModel were not initialized from the PyTorch model and are newly initialized: ['mpnet.pooler.dense.weight', 'mpnet.pooler.dense.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Define Keras model inputs
38 input_ids = tf.keras.Input(shape=(128,), dtype=tf.int32, name="input_ids")
39 attention_mask = tf.keras.Input(shape=(128,), dtype=tf.int32, name="attention_mask")
40
41 # Pass inputs through the transformer model using a Lambda layer
42 last_hidden_state = tf.keras.layers.Lambda(
43 wrap_transformer_model,
44 output_shape=(128, 768), # Explicitly specify the output shape
45 name="microsoft_mpnet-base",
46 )([input_ids, attention_mask])
47
48 # Reshape the output to fit into Conv2D (adding extra channel dimension) inside a Lambda layer
49 # def reshape_last_hidden_state(x):
50 # return tf.reshape(x, (-1, 1, 128, 768))
51 # reshaped_output = tf.keras.layers.Lambda(reshape_last_hidden_state)(last_hidden_state)
52 # Use Reshape layer to reshape the output to fit into Conv2D (adding extra channel dimension)
53 # Reshape to (batch_size, 128, 768, 1) for Conv2D input
54 reshaped_output = tf.keras.layers.Reshape((-1, 128, 768))(last_hidden_state)
55
56 # Add different layers to the model
57 x = tf.keras.layers.Conv2D(
58 512, (3, 3), activation="relu", padding="same", name="conv2d_1"
59 )(reshaped_output)
60 x = tf.keras.layers.BatchNormalization(name="batchnorm_1")(x)
61 x = tf.keras.layers.Dropout(0.3, name="dropout_1")(x)
62 x = tf.keras.layers.MaxPooling2D(pool_size=(2, 2), name="maxpool_1")(x)
63
64 x = tf.keras.layers.Conv2D(
65 256, (3, 3), activation="relu", padding="same", name="conv2d_2"
66 )(x)
67 x = tf.keras.layers.BatchNormalization(name="batchnorm_2")(x)
68 x = tf.keras.layers.Dropout(0.3, name="dropout_2")(x)
69 x = tf.keras.layers.MaxPooling2D(pool_size=(2, 2), name="maxpool_2")(x)
70
71 x = tf.keras.layers.Conv2D(
72 128, (3, 3), activation="relu", padding="same", name="conv2d_3"
73 )(x)
74 x = tf.keras.layers.BatchNormalization(name="batchnorm_3")(x)
75 x = tf.keras.layers.Dropout(0.4, name="dropout_3")(x)
76 x = tf.keras.layers.MaxPooling2D(pool_size=(2, 2), name="maxpool_3")(x)
77
78 # Add GlobalAveragePooling2D before the Dense layers
79 x = tf.keras.layers.GlobalAveragePooling2D(name="globalaveragepool")(x)
80
81 # Add Dense layers
82 x = tf.keras.layers.Dense(512, activation="relu", name="dense_1")(x)
83 x = tf.keras.layers.Dropout(0.5, name="dropout_4")(x)
84 x = tf.keras.layers.Dense(128, activation="relu", name="dense_2")(x)
85
86 # Add output layer (classification head)
87 dummy_output = tf.keras.layers.Dense(
88 2, activation="softmax", name="dummy_classification_head"
89 )(x)
90
91 # Wrap into a Keras model
92 wrapped_model = tf.keras.Model(inputs=[input_ids, attention_mask], outputs=dummy_output)
93
94 # https://github.com/keras-team/keras/blob/v3.3.3/keras/src/models/model.py#L217
95 # https://github.com/keras-team/keras/blob/master/keras/src/utils/summary_utils.py#L121
96 wrapped_model.summary(
97 line_length=None,
98 positions=None,
99 print_fn=None,
100 expand_nested=False,
101 show_trainable=True,
102 layer_range=None,
103 )
Model: "functional"
┏━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃ Connected to ┃ Trai… ┃
┡━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━┩
│ input_ids │ (None, 128) │ 0 │ - │ - │
│ (InputLayer) │ │ │ │ │
├───────────────────┼─────────────────┼───────────┼────────────────┼───────┤
│ attention_mask │ (None, 128) │ 0 │ - │ - │
│ (InputLayer) │ │ │ │ │
├───────────────────┼─────────────────┼───────────┼────────────────┼───────┤
│ microsoft_mpnet-… │ (None, 128, │ 0 │ input_ids[0][… │ - │
│ (Lambda) │ 768) │ │ attention_mas… │ │
├───────────────────┼─────────────────┼───────────┼────────────────┼───────┤
│ reshape (Reshape) │ (None, 1, 128, │ 0 │ microsoft_mpn… │ - │
│ │ 768) │ │ │ │
├───────────────────┼─────────────────┼───────────┼────────────────┼───────┤
│ conv2d_1 (Conv2D) │ (None, 1, 128, │ 3,539,456 │ reshape[0][0] │ Y │
│ │ 512) │ │ │ │
├───────────────────┼─────────────────┼───────────┼────────────────┼───────┤
│ batchnorm_1 │ (None, 1, 128, │ 2,048 │ conv2d_1[0][0] │ Y │
│ (BatchNormalizat… │ 512) │ │ │ │
├───────────────────┼─────────────────┼───────────┼────────────────┼───────┤
│ dropout_1 │ (None, 1, 128, │ 0 │ batchnorm_1[0… │ - │
│ (Dropout) │ 512) │ │ │ │
├───────────────────┼─────────────────┼───────────┼────────────────┼───────┤
│ maxpool_1 │ (None, 0, 64, │ 0 │ dropout_1[0][… │ - │
│ (MaxPooling2D) │ 512) │ │ │ │
├───────────────────┼─────────────────┼───────────┼────────────────┼───────┤
│ conv2d_2 (Conv2D) │ (None, 0, 64, │ 1,179,904 │ maxpool_1[0][… │ Y │
│ │ 256) │ │ │ │
├───────────────────┼─────────────────┼───────────┼────────────────┼───────┤
│ batchnorm_2 │ (None, 0, 64, │ 1,024 │ conv2d_2[0][0] │ Y │
│ (BatchNormalizat… │ 256) │ │ │ │
├───────────────────┼─────────────────┼───────────┼────────────────┼───────┤
│ dropout_2 │ (None, 0, 64, │ 0 │ batchnorm_2[0… │ - │
│ (Dropout) │ 256) │ │ │ │
├───────────────────┼─────────────────┼───────────┼────────────────┼───────┤
│ maxpool_2 │ (None, 0, 32, │ 0 │ dropout_2[0][… │ - │
│ (MaxPooling2D) │ 256) │ │ │ │
├───────────────────┼─────────────────┼───────────┼────────────────┼───────┤
│ conv2d_3 (Conv2D) │ (None, 0, 32, │ 295,040 │ maxpool_2[0][… │ Y │
│ │ 128) │ │ │ │
├───────────────────┼─────────────────┼───────────┼────────────────┼───────┤
│ batchnorm_3 │ (None, 0, 32, │ 512 │ conv2d_3[0][0] │ Y │
│ (BatchNormalizat… │ 128) │ │ │ │
├───────────────────┼─────────────────┼───────────┼────────────────┼───────┤
│ dropout_3 │ (None, 0, 32, │ 0 │ batchnorm_3[0… │ - │
│ (Dropout) │ 128) │ │ │ │
├───────────────────┼─────────────────┼───────────┼────────────────┼───────┤
│ maxpool_3 │ (None, 0, 16, │ 0 │ dropout_3[0][… │ - │
│ (MaxPooling2D) │ 128) │ │ │ │
├───────────────────┼─────────────────┼───────────┼────────────────┼───────┤
│ globalaveragepool │ (None, 128) │ 0 │ maxpool_3[0][… │ - │
│ (GlobalAveragePo… │ │ │ │ │
├───────────────────┼─────────────────┼───────────┼────────────────┼───────┤
│ dense_1 (Dense) │ (None, 512) │ 66,048 │ globalaverage… │ Y │
├───────────────────┼─────────────────┼───────────┼────────────────┼───────┤
│ dropout_4 │ (None, 512) │ 0 │ dense_1[0][0] │ - │
│ (Dropout) │ │ │ │ │
├───────────────────┼─────────────────┼───────────┼────────────────┼───────┤
│ dense_2 (Dense) │ (None, 128) │ 65,664 │ dropout_4[0][… │ Y │
├───────────────────┼─────────────────┼───────────┼────────────────┼───────┤
│ dummy_classifica… │ (None, 2) │ 258 │ dense_2[0][0] │ Y │
│ (Dense) │ │ │ │ │
└───────────────────┴─────────────────┴───────────┴────────────────┴───────┘
Total params: 5,149,954 (19.65 MB)
Trainable params: 5,148,162 (19.64 MB)
Non-trainable params: 1,792 (7.00 KB)
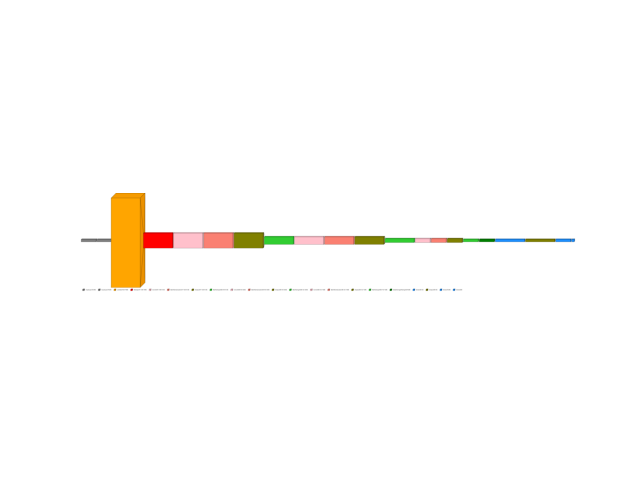
Visualize the wrapped model
107 img_nlp_mpnet_with_tf_layers = visualkeras.layered_view(
108 wrapped_model,
109 legend=True,
110 show_dimension=True,
111 min_z=1,
112 min_xy=1,
113 max_z=4096,
114 max_xy=4096,
115 scale_z=1,
116 scale_xy=1,
117 font={"font_size": 99},
118 text_callable="default",
119 # to_file="result_images/nlp_mpnet_with_tf_layers.png",
120 save_fig=True,
121 save_fig_filename="nlp_mpnet_with_tf_layers.png",
122 overwrite=False,
123 add_timestamp=True,
124 verbose=True,
125 )
126 img_nlp_mpnet_with_tf_layers
[INFO] Saving path to: /home/circleci/repo/galleries/examples/visualkeras_NLP/result_images/nlp_mpnet_with_tf_layers_20250724_060448Z.png
<matplotlib.image.AxesImage object at 0x7f837c10d710>
Total running time of the script: (0 minutes 10.607 seconds)
Related examples
Visualkeras: Spam Classification Conv1D Dense Example
Visualkeras: Spam Classification Conv1D Dense Example