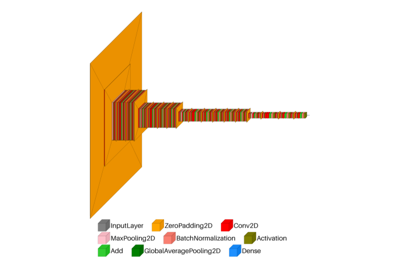
visualkeras: Vector Index DB#
An example showing the visualkeras function
used by a tf.keras.Model model.
# Authors: The scikit-plots developers
# SPDX-License-Identifier: BSD-3-Clause
# visualkeras Need aggdraw tensorflow
# !pip install scikitplot[core, cpu]
# or
# !pip install aggdraw
# !pip install tensorflow
# python -c "import tensorflow as tf, google.protobuf as pb; print('tf', tf.__version__); print('protobuf', pb.__version__)"
# python -m pip check
# If Needed
# pip install -U "protobuf<6"
# pip install protobuf==5.29.4
import tensorflow as tf
# Clear any session to reset the state of TensorFlow/Keras
tf.keras.backend.clear_session()
from scikitplot import visualkeras
import sys
# TODO: change this import to wherever your modified AnnoyIndex lives
# e.g. scikitplot.cexternals._annoy or similar
import scikitplot.cexternals._annoy as annoy
# from scikitplot import annoy
sys.modules["annoy"] = annoy # now `import annoy` will resolve to your module
import annoy
print(annoy.__doc__)
High-level Python interface for the C++ ANNoy backend.
Spotify ANNoy [1]_ (Approximate Nearest Neighbors Oh Yeah).
Exports:
* Annoy → low-level C-extension type (stable) `c-api powered new features <https://scikit-plots.github.io/dev/modules/generated/scikitplot.cexternals._annoy.Annoy.html>`_
* AnnoyIndex → alias of Annoy (legacy AnnoyIndex name)
.. seealso::
* :ref:`ANNoy <annoy-index>`
* :ref:`cexternals/ANNoy <cexternals-annoy-index>`
* https://github.com/spotify/annoy
* https://pypi.org/project/annoy
References
----------
.. [1] `Spotify AB. (2013). "Approximate Nearest Neighbors Oh Yeah"
Github. https://github.com/spotify/annoy <https://github.com/spotify/annoy>`_
Examples
--------
>>> import random; random.seed(0)
>>> # from annoy import Annoy, AnnoyIndex
>>> from scikitplot.cexternals._annoy import Annoy, AnnoyIndex
>>> from scikitplot.annoy import Annoy, AnnoyIndex, Index
>>> f = 40 # vector dimensionality
>>> t = AnnoyIndex(f, "angular") # Length of item vector and metric
>>> t.add_item(0, [1] * f)
>>> t.build(10) # Build 10 trees
>>> t.get_nns_by_item(0, 1) # Find nearest neighbor
Total running time of the script: (0 minutes 0.578 seconds)
Related examples