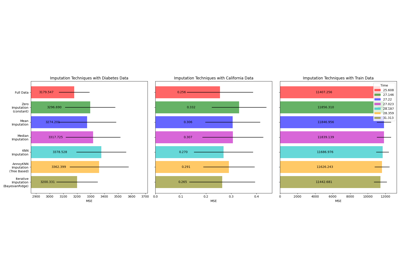
AnnoyKNNImputer#
- class scikitplot.impute.AnnoyKNNImputer(*, missing_values=nan, n_trees=-1, search_k=-1, n_neighbors=5, weights='uniform', metric='euclidean', index_nan_strategy='skip', copy=True, add_indicator=False, keep_empty_features=False, n_jobs=None, random_state=None)[source]#
Fast approximate KNN-based imputation using Spotify’s Annoy library.
This imputer replaces the exact neighbor search of
KNNImputerwith a tree-based approximate nearest neighbor index (Annoy), providing significant scalability improvements on large datasets.- Parameters:
- missing_valuesint, float, str, np.nan or None, default=np.nan
The placeholder for the missing values. All occurrences of
missing_valueswill be imputed. For pandas’ dataframes with nullable integer dtypes with missing values,missing_valuesshould be set to np.nan, sincepd.NAwill be converted to np.nan.- n_treesint, default=-1
Number of trees in the Annoy forest. More trees improve neighbor accuracy at the cost of build time and memory. If -1, trees are built dynamically until the index reaches roughly twice the number of items (heuristic:
_n_nodes >= 2 * n_items). Guidelines:Small datasets (<10k samples): 10-20 trees.
Medium datasets (10k-1M samples): 20-50 trees.
Large datasets (>1M samples): 50-100+ trees.
- search_kint or None, default=-1
Number of nodes inspected during neighbor search. Larger values yield more accurate but slower queries. If -1, defaults to
n_trees * n_neighbors.- n_neighborsint, default=5
Number of neighboring samples used for imputation. Higher values produce smoother imputations but may reduce locality.
- weights{‘uniform’, ‘distance’} or callable, default=’uniform’
Weighting strategy for neighbor contributions:
'uniform': all neighbors have equal weight.'distance': inverse-distance weighting, where closer neighbors contribute more (w_ik = 1 / (1 + d(x_i, x_k))).callable : custom function taking an array of distances and returning an array of weights.
- metric{‘angular’, ‘euclidean’, ‘manhattan’, ‘hamming’, ‘dot’}, default=’euclidean’
Distance metric used for nearest-neighbor search:
'angular': Cosine similarity (angle only, ignores magnitude). Best for normalized embeddings (e.g., text embeddings, image features).'euclidean': L2 distance, defined as √Σ(xᵢ - yᵢ)². Standard geometric distance, sensitive to scale.'manhattan': L1 (City-block) distance, defined as Σ|xᵢ - yᵢ|. More robust to outliers than L2, still scale-sensitive.'hamming': Fraction or count of of differing elements. Suitable for binary or categorical features (e.g., 0/1).'dot': Negative inner product (-x·y). Sensitive to both direction and magnitude of vectors.
- index_nan_strategy{‘mean’, ‘median’, ‘skip’} or None, default=’skip’
Strategy to handle NaNs when building the Annoy index. Rows containing NaNs cannot be indexed directly. The temporary fill affects only index construction, not the final imputed values.
'mean': fill NaNs with the column mean.'median': fill NaNs with the column median.'skip'orNone: skip rows with NaNs during index build.
- copybool, default=True
If True, a copy of X will be created. If False, imputation will be done in-place whenever possible.
- add_indicatorbool, default=False
If True, a
MissingIndicatortransform will stack onto the output of the imputer’s transform. This allows a predictive estimator to account for missingness despite imputation. If a feature has no missing values at fit/train time, the feature won’t appear on the missing indicator even if there are missing values at transform/test time.- keep_empty_featuresbool, default=False
If True, features that consist exclusively of missing values when
fitis called are returned in results whentransformis called. The imputed value is always0.- n_jobsint or None, default=None
Specifies the number of threads used to build the trees.
n_jobs=-1uses all available CPU cores.- random_stateint or None, default=None
Seed for Annoy’s random hyperplane generation.
- Attributes:
- indicator_
MissingIndicator Indicator used to add binary indicators for missing values.
Noneif add_indicator is False.- n_features_in_int
Number of features seen during fit.
- feature_names_in_ndarray of shape (
n_features_in_,) Names of features seen during fit. Defined only when
Xhas feature names that are all strings.
- indicator_
See also
sklearn.impute.KNNImputerMultivariate imputer that estimates missing features using nearest samples. Exact KNN-based imputer using brute-force search.
Notes
For each sample \(x_i\) and feature \(j\), the imputed value is:
\[\hat{x}_{ij} = \frac{\sum_{k \in N_i} w_{ik} x_{kj}}{\sum_{k \in N_i} w_{ik}}\]where \(N_i\) is the set of K nearest neighbors of \(x_i\), and \(w_{ik}\) is the neighbor weight:
\[w_{ik} = \frac{1}{1 + d(x_i, x_k)}\]Annoy provides approximate neighbor search, so imputations are not exact.
The index remains in memory after fitting for efficient queries.
Annoy supports specific metrics;
'euclidean'(p=2) and'manhattan'(p=1) are special cases of the Minkowski distance.
References
Examples
>>> import numpy as np >>> from scikitplot.impute import AnnoyKNNImputer >>> X = np.array([[1, 2, np.nan], [3, 4, 3], [np.nan, 6, 5], [8, 8, 7]]) >>> imputer = AnnoyKNNImputer(n_trees=5, n_neighbors=5) >>> imputer.fit_transform(X) array([[1. , 2. , 4. ], [3. , 4. , 3. ], [5.5, 6. , 5. ], [8. , 8. , 7. ]])
- fit_transform(X, y=None, **fit_params)[source]#
Fit to data, then transform it.
Fits transformer to
Xandywith optional parametersfit_paramsand returns a transformed version ofX.- Parameters:
- Xarray-like of shape (n_samples, n_features)
Input samples.
- yarray-like of shape (n_samples,) or (n_samples, n_outputs), default=None
Target values (None for unsupervised transformations).
- **fit_paramsdict
Additional fit parameters.
- Returns:
- X_newndarray array of shape (n_samples, n_features_new)
Transformed array.
- get_feature_names_out(input_features=None)[source]#
Return output feature names, including indicator features if used.
- get_metadata_routing()[source]#
Get metadata routing of this object.
Please check User Guide on how the routing mechanism works.
- Returns:
- routingMetadataRequest
A
MetadataRequestencapsulating routing information.
- get_params(deep=True)[source]#
Get parameters for this estimator.
- Parameters:
- deepbool, default=True
If True, will return the parameters for this estimator and contained subobjects that are estimators.
- Returns:
- paramsdict
Parameter names mapped to their values.
- set_output(*, transform=None)[source]#
Set output container.
See Introducing the set_output API for an example on how to use the API.
- Parameters:
- transform{“default”, “pandas”, “polars”}, default=None
Configure output of
transformandfit_transform."default": Default output format of a transformer"pandas": DataFrame output"polars": Polars outputNone: Transform configuration is unchanged
Added in version 1.4:
"polars"option was added.
- Returns:
- selfestimator instance
Estimator instance.
- set_params(**params)[source]#
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters:
- **paramsdict
Estimator parameters.
- Returns:
- selfestimator instance
Estimator instance.