plot_residuals_distribution#
- scikitplot.api.metrics.plot_residuals_distribution(y_true, y_pred, *, dist_type='normal', var_power=1.5, title='Precision-Recall AUC Curves', title_fontsize='large', text_fontsize='medium', cmap=None, show_labels=True, digits=4, figsize=(10, 5), nrows=1, ncols=3, index=3, **kwargs)[source]#
Plot residuals and fit various distributions to assess their goodness of fit.
- Parameters:
- y_truearray-like, shape (n_samples,)
Ground truth (correct) target values.
- y_predarray-like, shape (n_samples,)
Estimated targets as returned by a classifier.
- dist_typestr, optional, default=’normal’
Type of distribution to fit to the residuals. Options are:
‘normal’: For symmetrically distributed residuals (mean μ, std σ).
‘poisson’: For count-based residuals or rare events (mean λ).
‘gamma’: For positive, skewed residuals with a heavy tail (shape k or α, scale θ or β).
- ‘inverse_gaussian’: For residuals with a distribution similar to the inverse Gaussian
(mean μ, scale λ).
‘exponential’: For non-negative residuals with a long tail (scale λ).
- ‘lognormal’: For positively skewed residuals with a multiplicative effect
(shape σ, scale exp(μ)).
‘tweedie’: For complex data including counts and continuous components.
The Tweedie distribution can model different types of data based on the variance power (
var_power):var_power = 0: Normal distribution (mean μ, std σ)
var_power = 1: Poisson distribution (mean λ)
1 < var_power < 2: Compound Poisson-Gamma distribution
var_power = 2: Gamma distribution (shape k, scale θ)
var_power = 3: Inverse Gaussian distribution (mean μ, scale λ)
- var_powerfloat or None
- The variance power for the Tweedie distribution, applicable if
dist_type='tweedie'. Default is 1.5, which means Tweedie-specific plotting.
Example values: 1.5 for Compound Poisson-Gamma distribution, 2 for Gamma distribution.
- The variance power for the Tweedie distribution, applicable if
- titlestr, optional, default=’Precision-Recall AUC Curves’
Title of the generated plot.
- title_fontsizestr or int, optional, default=’large’
Font size for the plot title.
- text_fontsizestr or int, optional, default=’medium’
Font size for the text in the plot.
- cmapNone, str or matplotlib.colors.Colormap, optional, default=None
Colormap used for plotting. Options include ‘viridis’, ‘PiYG’, ‘plasma’, ‘inferno’, ‘nipy_spectral’, etc. See Matplotlib Colormap documentation for available choices.
https://matplotlib.org/stable/users/explain/colors/index.html
plt.colormaps()
plt.get_cmap() # None == ‘viridis’
- show_labelsbool, optional, default=True
Whether to display the legend labels.
- digitsint, optional, default=3
Number of digits for formatting PR AUC values in the plot.
Added in version 0.3.9.
- **kwargs: dict
Generic keyword arguments.
- Returns:
- axmatplotlib.axes.Axes
The axes on which the plot was drawn.
- Other Parameters:
- axmatplotlib.axes.Axes, optional, default=None
The axis to plot the figure on. If None is passed in the current axes will be used (or generated if required).
Added in version 0.4.0.
- figmatplotlib.pyplot.figure, optional, default: None
The figure to plot the Visualizer on. If None is passed in the current plot will be used (or generated if required).
Added in version 0.4.0.
- figsizetuple, optional, default=None
Width, height in inches. Tuple denoting figure size of the plot e.g. (12, 5)
Added in version 0.4.0.
- nrowsint, optional, default=1
Number of rows in the subplot grid.
Added in version 0.4.0.
- ncolsint, optional, default=1
Number of columns in the subplot grid.
Added in version 0.4.0.
- plot_stylestr, optional, default=None
Check available styles with “plt.style.available”. Examples include: [‘ggplot’, ‘seaborn’, ‘bmh’, ‘classic’, ‘dark_background’, ‘fivethirtyeight’, ‘grayscale’, ‘seaborn-bright’, ‘seaborn-colorblind’, ‘seaborn-dark’, ‘seaborn-dark-palette’, ‘tableau-colorblind10’, ‘fast’].
Added in version 0.4.0.
- show_figbool, default=True
Show the plot.
Added in version 0.4.0.
- save_figbool, default=False
Save the plot. Used by
save_plot_decorator.Added in version 0.4.0.
- save_fig_filenamestr, optional, default=’’
Specify the path and filetype to save the plot. If nothing specified, the plot will be saved as png inside
result_imagesunder to the current working directory. Defaults to plot image named to usedfunc.__name__. Used bysave_plot_decorator.Added in version 0.4.0.
- overwritebool, optional, default=True
If False and a file exists, auto-increments the filename to avoid overwriting.
Added in version 0.4.0.
- add_timestampbool, optional, default=False
Whether to append a timestamp to the filename. Default is False.
Added in version 0.4.0.
- verbosebool, optional
If True, enables verbose output with informative messages during execution. Useful for debugging or understanding internal operations such as backend selection, font loading, and file saving status. If False, runs silently unless errors occur.
Default is False.
Added in version 0.4.0: The
verboseparameter was added to control logging and user feedback verbosity.
- Raises:
- ValueError: If an unsupported distribution type is provided or if
var_poweris invalid.
- ValueError: If an unsupported distribution type is provided or if
Examples
>>> import numpy as np ... ... np.random.seed(0) >>> from sklearn.datasets import ( ... load_diabetes as data_regression, ... ) >>> from sklearn.model_selection import train_test_split >>> from sklearn.linear_model import Ridge >>> import scikitplot as skplt >>> >>> X, y = data_regression(return_X_y=True, as_frame=False) >>> X_train, X_val, y_train, y_val = train_test_split( ... X, y, test_size=0.5, random_state=0 ... ) >>> model = Ridge(alpha=1.0).fit(X_train, y_train) >>> y_val_pred = model.predict(X_val) >>> skplt.metrics.plot_residuals_distribution( >>> y_val, y_val_pred, dist_type='tweedie', >>> );
(
Source code,png)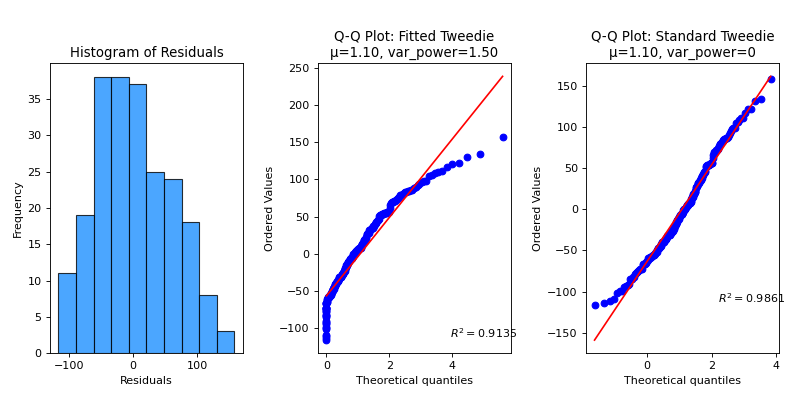
{kind=link}